はじめに
医療分野に限定してトピックモデル・・・なかでもLDA、およびその派生・・・を利用した文献を漁ってみた。
最初はCiNiiやPubMedで検索していたが、フリーで手に入るものは圧倒的にGoogleの検索結果が充実している。
トピックモデルと言えばテキストマイニングが多いが、医療分野ではカルテをマイニングするだけでなく、問診票や電子レセプトをLDAやその派生形を使って解析する例も見られ、大変興味深い。
今後少しずつ読んでまとめていきたい。
[1] 問診データに対する潜在トピックモデルに基づく健診データ解析
問診票をドキュメント、問診項目を単語、被験者の生活習慣を潜在トピックとしてLDAを用いてトピック分析を行ったという研究。
被験者を出現率が最大となるトピックで分類し、各被験者群の間で検査値データに違いがあるかどうかでモデルの評価を行っている。
一般に、トピックモデルは教師なし学習であるため評価が難しいとされている。さらにトピックを人間が解釈するのも難しいとされている。したがって何をもってモデルが妥当か評価するのは難しい。そこでよく行われるのが外部基準を使って適切に分類されているかを検証するという手法である。この研究では外部基準として検査値を使用している。つまり、トピックモデルで分類された被験者群の間で検査値に有意な違いがあるかどうかでモデルの妥当性を検証している。
しかし、そもそも「トピックモデルで分類された被験者」とは一体何だろう?トピックモデルは潜在トピックを抽出する手法であり、対象(この場合は被験者)を分類するものではない(べつに分類してもいいけど・・・)。しかし、潜在トピックに意味付けができない以上、それらがどのくらい含まれているかを議論しても意味がない。そこで、最も含まれる割合が高いトピックで被験者を分類している。また、そのようにしてもよいことをネットワークグラフでクラスタリングされた群と比較して検証している。ここで、ネットワークグラフを構築する上で被験者間の類似性をJensen-Shannon divergenceによって計算し、それがある閾値(ここでは0.05としている)より小さい場合にノード間(被験者間)にエッジを設けてネットワークグラフを作成している。クラスタリングはNewmannアルゴリズムを使って被験者を群に分け、それが最大トピック成分で分類したものと同等であることを示している。
この文献には様々な手法(Jensen-Shannon divergence, ネットワークグラフ理論, Newmannアルゴリズム, concordance)が用いられており、非常に示唆に富む。何より問診票の問診項目を単語に見立ててトピックモデルを適用しているのが秀逸である。考えてみれば、Recommendation分析も商品アイテムを単語とみなして解析を行っているのだから、それと同じと言えば同じであるが。
畠山 豊, 宮野 伊知郎, 片岡 浩巳, 中島 典昭, 渡部 輝明, 奥原 義保: 問診データに対する潜在トピックモデルに基づく健診データ解析. 医療情報学, 33(5), 2013.
Hatakeyama Y, Miyano I, Kataoka H, Nakajima N, Watabe T, Yasuda N, Okuhara Y: Use of a Latent Topic Model for Characteristic Extraction from Health Checkup Questionnaire Data. Methods Inf Med. 54(6), 515-21, 2015.
[2] A Most Resource-Consuming Disease Estimation Method from Electronic Claim Data Based on Labeled LDA
電子レセプトをドキュメント、診療行為を単語、疾患を潜在トピックとみなして、最も医療資源を使った疾患を推定するといった内容の研究。ただし、ここではただのLDAではなく"Labeled LDA"なるものを使っている。
Labeled LDAというものをよく知らないが、この論文によると「ラベル付きの文書コレクションを生成するためのプロセスを記述する確率的トピックモデル」と書いてある。
図1が論文中に示されたグラフィカルモデルである。

Labeled LDAというものをよく知らないが、この論文によると「ラベル付きの文書コレクションを生成するためのプロセスを記述する確率的トピックモデル」と書いてある。
図1が論文中に示されたグラフィカルモデルである。

通常のLDAに比べてΦ→λ→θが付け加わっている。λはトピックの有無を示すインディケータで、Φはその事前分布ということである。この図でλとwにハッチが付けられているので、これら2つが観測されるデータなのであろう。
どのようにしてモデルを生成するのかこの論文を読んでもよくわからなかった。特にλの正体がわからない。ノーテーションも λ と思われる箇所が l になっていたりして、間違っているのか、それとも自分の理解不足なのかもわからない。
検証は、モデルがはじき出したトピック(すなわち疾患)が電子レセプトに人手でつけられた疾患(DPC病名と思われる)に一致するかどうかで行っている。ここで、「モデルがはじき出したトピック」は、単に構成比率(つまりθ_{d,k})が最大の疾患というのではなく、料金(点数)が最大の疾患としている点がポイントである。「最も医療資源を投入した」というのを「最もコストのかかった」と解釈してのことだろう。
しかし、この「コスト(点数)」はどのようにしてモデルに取り込んだのであろうか?通常の文書を対象としたLDAでは単語の出現頻度が重みの役割を果たす。この研究では医療行為の点数を頻度の代わりに使っているのだろうか?そのあたりが読み取れない。
また、盛んに疾患(つまりλ?)が分かっていなくとも問題ないといった記述がみられるが、これがどういうことなのかわからない。ラベル付きLDAなんだからラベル(つまり疾患)がデータとして与えられなかったら機能しないだろうと思うのだが。
モデルの評価方法は文献[1]と同じで「正解」(人手で付けたDPC病名)とモデルが分類した結果を比較している。
評価指標はRecall(再現率)、Precision(精度)、F-value(F値)で、SVMとナイーブベイズと比較し、かなり良い結果が得られたと述べている。
ここでもトピックモデルを分類に使っているが、文献[1]と違って構成比率(つまりθ_{d,k})が最大のトピックには「最も医療資源を使った疾患」という大義名分があるのでトピックモデルの使い方としては間違っていないと感じた。
どのようにしてモデルを生成するのかこの論文を読んでもよくわからなかった。特にλの正体がわからない。ノーテーションも λ と思われる箇所が l になっていたりして、間違っているのか、それとも自分の理解不足なのかもわからない。
検証は、モデルがはじき出したトピック(すなわち疾患)が電子レセプトに人手でつけられた疾患(DPC病名と思われる)に一致するかどうかで行っている。ここで、「モデルがはじき出したトピック」は、単に構成比率(つまりθ_{d,k})が最大の疾患というのではなく、料金(点数)が最大の疾患としている点がポイントである。「最も医療資源を投入した」というのを「最もコストのかかった」と解釈してのことだろう。
しかし、この「コスト(点数)」はどのようにしてモデルに取り込んだのであろうか?通常の文書を対象としたLDAでは単語の出現頻度が重みの役割を果たす。この研究では医療行為の点数を頻度の代わりに使っているのだろうか?そのあたりが読み取れない。
また、盛んに疾患(つまりλ?)が分かっていなくとも問題ないといった記述がみられるが、これがどういうことなのかわからない。ラベル付きLDAなんだからラベル(つまり疾患)がデータとして与えられなかったら機能しないだろうと思うのだが。
モデルの評価方法は文献[1]と同じで「正解」(人手で付けたDPC病名)とモデルが分類した結果を比較している。
評価指標はRecall(再現率)、Precision(精度)、F-value(F値)で、SVMとナイーブベイズと比較し、かなり良い結果が得られたと述べている。
ここでもトピックモデルを分類に使っているが、文献[1]と違って構成比率(つまりθ_{d,k})が最大のトピックには「最も医療資源を使った疾患」という大義名分があるのでトピックモデルの使い方としては間違っていないと感じた。
Yasutaka Hatakeyama, Takahiro Ogawa, Hironori IKEDA, Miki Haseyama: A Most Resource-Consuming Disease Estimation Method from Electronic Claim Data Based on Labeled LDA. IEICE Transactions on Information and Systems E99.D(3):763-768, 2016.
(6)式の右辺は内積であることに注意する。point(w_{d})は請求dの診療行為に対応する点数を要素に持つ行ベクトルである。一方,I(k,w_{d})は,請求dの診療行為が当該疾患kに投入されたものかどうかを示すインディケータを要素とする列ベクトルである。これらの内積を計算することで当該請求において疾患kに投入された医療資源の点数が計算できる。
【補足】
もう一度読み返してみた。前読んだ時分からなかったことがいくらか分かるようになった。通常のLDAではドキュメントがすべてのトピックを含みうるが,Labeled LDAではドキュメントごとに含みうるトピックが異なり,それが「ラベル」ということらしい。つまり,DPCデータ(請求データ)にはいくつかの疾患が割り当てられており(併存症)それが当該DPCデータにおける「ラベル」になる。Labeld LDAは,これらの疾患の構成比率(含有率)θ_{d,k}と疾患ごとの診療行為の割合β_{k,w}を求め,(8)式によって与えられた請求データにおける疾患kが診療行為w_{d,i}を含む確率を求める。さらに,当該請求データの診療行為が疾患kに投入されたものであるか否かのインディケータを(7)式から計算し,それを用いて(6)式から疾患kに費やしたコスト(点数)を計算している。これが最大になる疾患kが最も医療資源を投入した疾患というわけである。(6)式の右辺は内積であることに注意する。point(w_{d})は請求dの診療行為に対応する点数を要素に持つ行ベクトルである。一方,I(k,w_{d})は,請求dの診療行為が当該疾患kに投入されたものかどうかを示すインディケータを要素とする列ベクトルである。これらの内積を計算することで当該請求において疾患kに投入された医療資源の点数が計算できる。
[3]Adverse Drug Reaction Prediction with Symbolic Latent Dirichlet Allocation
医薬品文書をドキュメント、薬物副作用用語(ADR terms)を単語、医薬品文書にまたがって頻繁に現れる薬物副作用用語の集合をトピックとみなして3種類のLDA類似モデルを構築し、副作用(ADR)を予測するといった内容の研究である。
副作用の予測を行うために、まず対象とする医薬品を特徴づけるADRトピック分布を求め、次に薬物構造の特徴(features)をADRトピック分布と関連付けるために予測モデルを構築する。その後、その医薬品に関連する副作用を、そのトピック分布を通じて予測することができる。
この論文では3つのモデルが検討されている。まず、基本となるモデルのグラフィカルモデルを図1に示す。
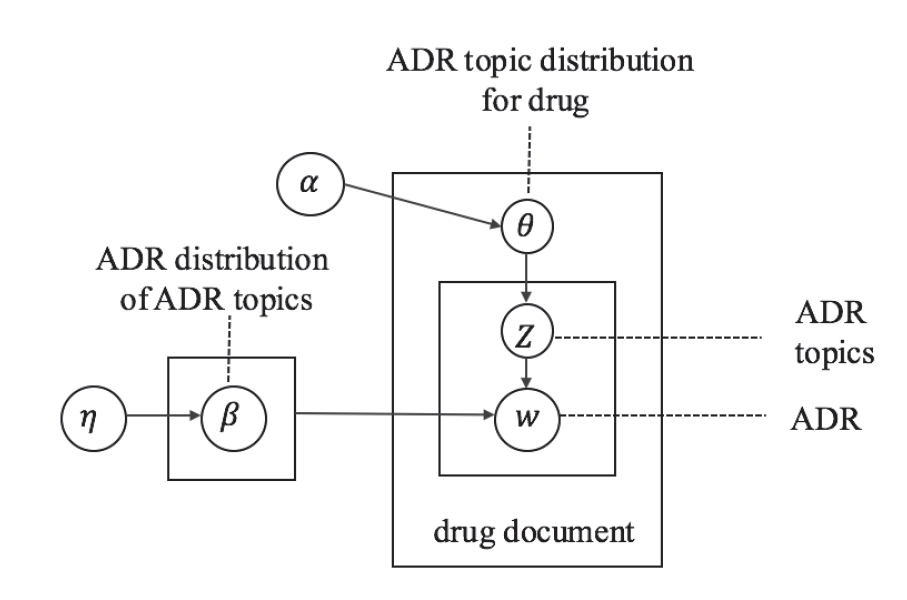 |
| 図1.ベースモデル(The base model) |
ベースモデルはLDAをそのまま利用したものである。
次にドメイン知識を採り入れた正規化モデル(The regularized rodel)のグラフィカルモデルを図2に示す。
 |
| 図2.正規化モデル(The regularized rodel) |
具体的には同じトピックを持つ子ADRが異なる親ADRを持つ場合にペナルティーを科す。
最後に混合入力モデル(The mixed input model)のグラフィカルモデルを図3に示す。
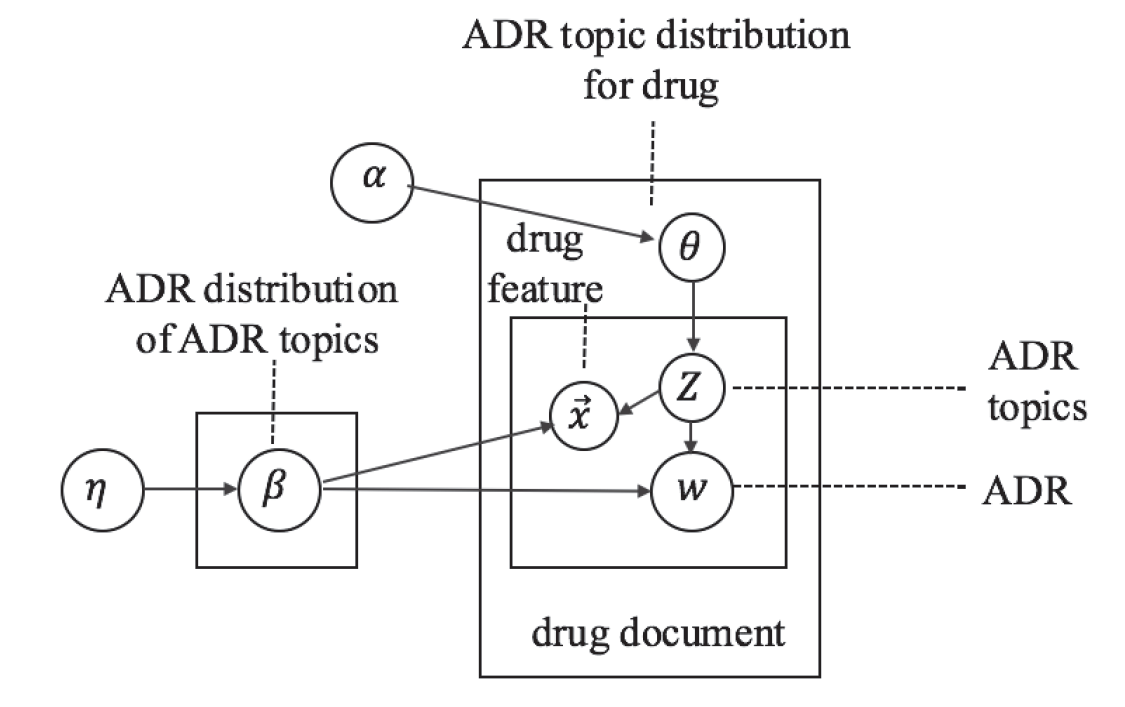 |
| 図3.混合入力モデル(The mixed input model) |
これは、入力となるADR用語と薬剤構造の特徴(feature)を別々に学習する代わりにADR用語と薬剤構造の特徴(図3のx)の特徴の両方を医薬品文書の単語として扱う。これによって学習速度が大幅に向上する。
構築したモデルはADReCSという副作用データベースを用いて評価を行っている。そして他の手法(lasso、CC: canonical correlation analysis)とROCのAUC(Area Under Curve)やPR(Precision-Recallのことだろうか?)のAUCを使って比較している。
ということは、やはり外的な基準(教師データ)を用いて分類問題に帰着させているのだろうか・・・。このあたりが読み取れなかった。
Cao Xiao, Ping Zhang, W. Art Chaowalitwongse, Jianying Hu, Fei Wang: Adverse Drug Reaction Prediction with Symbolic Latent Dirichlet Allocation. Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), 2017.


0 件のコメント:
コメントを投稿