この論文は、ChatGPTにアメリカの医師国家試験を解かせたらどんな成績になるだろうということを実験したものだ。いかにもあるあるの研究テーマだ。結果として、ChatGPTは3年生の医学生の合格点に相当すると述べている。
ChatGPTを研究ネタにするとき、こういった試験問題を解かせるというのはよくある話だ。医療情報技師の認定試験についても同様のことをやってみると面白いだろうなと思う。
そんなことを思っていたら、4/29に、こんな論文を見つけた。
これは、日本の医師国家試験をChatGPTに解かせたら55%の正答率だったという論文(4/10朝日新聞)。
さらに、5/1には、m3.comのニュース記事「Chat-GPTが第117回医師国試で合格点」から次のような論文を見つけた。
これは、上記と同じく、日本の医師国家試験をChatGPTに解かせたという論文で、前出の論文と違って、今度は合格したという内容。ポイントは、①日本語の問題文を英訳してChatGPTに入力したこと、②プロンプト・エンジニアリング(問題タイプごとに出力フォーマットを変更した)、③GPT-4を使用した、ことが功を奏したという点。そういえば、前出の論文にも、ChatGPTが学習した英文のデータ量は、日本語のよりも16.6倍もあり、プロンプトに英文で入力したほうが日本語で入力するより効果が大きいのではないかと考察していたが、それがドンピシャだったことがこの論文から伺える。
----------------------------------------
Abstract
----------------------------------------
Background:
Chat Generative Pre-trained Transformer (ChatGPT) は、ユーザー入力に対する会話スタイルの応答を生成できる、1,750 億のパラメーターを持つ自然言語処理モデルです。
Objective:
この調査の目的は、米国医師免許試験のステップ 1 およびステップ 2 試験の範囲内の質問に対する ChatGPT のパフォーマンスを評価し、ユーザーの解釈可能性について回答を分析することでした。
Methods:
ChatGPT のパフォーマンスを評価するために、ステップ 1 とステップ 2 に関連する質問を含む 2 セットの多肢選択問題を使用しました。最初のセットは、医学生向けに一般的に使用されている問題バンクである AMBOSS から派生したもので、問題の難易度とユーザーベースに関連する試験の成績に関する統計も提供します。2 番目のセットは、National Board of Medical Examiners (NBME) の無料の 120 の質問でした。ChatGPT のパフォーマンスは、他の 2 つの大きな言語モデルである GPT-3 と InstructGPT と比較されました。各 ChatGPT 応答のテキスト出力は、選択された回答の論理的正当性、質問の内部情報の存在、および質問の外部情報の存在という 3 つの定性的な指標にわたって評価されました。
Results:
AMBOSS-Step1、AMBOSS-Step2、NBME-Free-Step1、NBME-Free-Step2 の 4 つのデータ セットにたいして、ChatGPT は、それぞれ 44% (44/100)、42% (42/100)、64.4% ( 56/87)、および 57.8% (59/102)の精度を達成しました。ChatGPT は、すべてのデータ セットで平均 8.15% InstructGPT を上回り、GPT-3 は偶然と同様のパフォーマンスを示しました。このモデルは、AMBOSS-Step1 データセット内で質問の難易度が上がるにつれて (P=.01)、パフォーマンスが大幅に低下することを示しました。ChatGPT の回答選択の論理的正当性は、NBME データセットの出力の 100% に存在することがわかりました。質問に対する内部情報は、すべての質問の 96.8% (183/189) に存在していました。問題外の情報の存在は、NBME-Free-Step1 (P<.001) および NBME-Free-Step2 (P=.001) データセットの正解に比べて、不正解で、それぞれ 44.5%、27% 低かった。
Conclusions:
ChatGPT は、医療質問応答のタスクにおける自然言語処理モデルの大幅な改善を示しています。NBME-Free-Step-1 データセットで 60% を超えるしきい値で実行することにより、モデルが 3 年生の医学生の合格点に相当することを示します。さらに、ChatGPT が大部分の回答でロジックと情報コンテキストを提供できることを強調しています。これらの事実を総合すると、学習をサポートするためのインタラクティブな医学教育ツールとしての ChatGPT の潜在的なアプリケーションの説得力のある事例になります。
----------------------------------------
Introduction
----------------------------------------
Chat Generative Pre-trained Transformer (ChatGPT) [1] は、膨大な量のデータでトレーニングされたディープ ラーニング アルゴリズムを使用して、ユーザー プロンプトに対して人間のような応答を生成する 1,750 億パラメーターを持つ自然言語処理モデルです [2]。汎用対話的エージェントとして、ChatGPT は幅広いトピックに対応できるように設計されており、カスタマー サービス、チャットボット、およびその他の多くのアプリケーションのホストとして役立つツールになる可能性があります。リリース以来、シェイクスピアのソネット(14行詩)のスタイルで応答を自動的に生成するなど、一見信じられないほどの偉業を成し遂げた一方で、単純な数学的な質問に答えることができなかった [3-5]ことについて、かなりの報道がなされました。
ChatGPT は、自己回帰言語モデル [6] として知られる大規模言語モデル (LLM) のクラスの中で最新のものです。ChatGPT に似ていると考えられる生成 LLM は、トランスフォーマー モデル [7] のデコーダー コンポーネントを使用してトレーニングされ、テキストの大規模なコーパス [8-10] でシーケンス内の次のトークンを予測するタスクが課せられます。このような基盤モデルは、多くの場合、パフォーマンスを向上させるためにタスク固有のデータで微調整されます。しかし、OpenAI の GPT-3 の紹介では、微調整をほとんど必要とせずに最先端のパフォーマンスを実現する高度にスケーリングされた LLM の最初の製品と述べています[6]。ChatGPT は、OpenAI の以前の GPT-3.5 言語モデルに基づいて構築されており、教師あり学習と強化学習の両方の手法が追加されています [1]。ChatGPT は、OpenAI アプリケーション プログラミング インターフェイス (API)である Playground に入力されたプロンプトに対する人間が作成した応答でトレーニングされた GPT-3.5 の微調整バージョンである InstructGPT の直接の子孫です。InstructGPT は、最初に特定のプロンプトに対する一連の応答を生成するタスクを課され、人間のアノテーターが優先回答にラベルを付けるように開発されました。これらの好みは、InstructGPT を調整するために、強化学習アルゴリズムである PPO (Proximal Policy Optimization) を使用してトレーニングされた報酬モデルで最大化されます。ChatGPT は、対話型の出力を促進するために会話プロンプトで特別にトレーニングされていると報告されています。
医療分野では、LLM は、個別化された患者とのやり取りや患者の健康教育のためのツールとして研究されてきました [11,12]。可能性を示していますが、これらのモデルは、(生成的な) 質問応答タスクを通じて臨床知識をテストすることに成功していません [13,14]。ChatGPT は、臨床知識と対話的相互作用の組み合わせをより適切に表現する可能性のある新しい一連のモデルの最初のモデルとなる可能性があります。独自の語り口の応答を生成する ChatGPT のインターフェイスにより、シミュレートされた患者、個々のフィードバックを提供するブレインストーミング ツール、または小グループ スタイルの学習をシミュレートする仲間のクラスメートとしての行動など、斬新なユース ケースが可能になります。ただし、これらのアプリケーションが有用であるためには、ユーザーが応答に十分な信頼を持てるように、ChatGPT は医学知識の評価と推論で人間と同等のパフォーマンスを発揮する必要があります。
この論文では、①医学知識(確立された上で、なお進化している生物医学、臨床、疫学、および社会行動科学の知識)の主要な能力と②米国医師免許試験 (USMLE) のステップ 1 およびステップ 2 の臨床知識試験でテストされた知識を中心とした 2 つのデータ セットの使用を通して患者ケアへの適用の側面を評価しようとする試験でのChatGPTのパフォーマンスを定量化することを目的としました。ステップ 1 では、基礎科学と医学の実践との関係に焦点を当てていますが、ステップ 2 では、これらの基礎科学の臨床応用に焦点を当てています。USMLE ステップ 3 は、基本的な知識ではなく、独立した総合診療科の医療行為のスキルと能力を評価することを目的としているため、除外されました。また、これらの試験での ChatGPT のパフォーマンスを、以前の 2 つの LLM、GPT-3 および InstructGPT のパフォーマンスと比較しました。さらに、ChatGPT が、シミュレートされた医療家庭教師として機能する能力をさらに評価するために、論理的な正当化と内部からのおよび外部からの情報の使用に関して、ChatGPT の応答の整合性を定性的に調べました。
----------------------------------------
Methods
----------------------------------------
Medical Education Data Sets
ステップ1とステップ2に関連するChatGPTの医学的知識の理解を調べるために、2組のデータセットを作成しました。最初に、2700 を超えるステップ 1 と 3150 を超えるステップ 2 の質問を含む、広く使用されている質問バンクである AMBOSS から 100 の質問のサブセットを選択しました [15]。以前の AMBOSS ユーザーからの既存のパフォーマンス統計により、モデルの相対的なパフォーマンスを判断できます。これらのデータ セットを AMBOSS-Step1 および AMBOSS-Step2 と呼びます。これらのヒントを含む各質問の 2 番目のインスタンスをデータ セットに含めて、ヒントによって提供される追加のコンテキストがパフォーマンスを向上させるかどうかを判断しました。
また、National Board of Medical Examiners (NBME) によって開発された 120 の無料のステップ 1 およびステップ 2 の臨床知識問題のリストも使用しました。これは、それぞれ NBME-Free-Step1 および NBME-Free-Step2 と呼ばれ、本当の医師免許試験の問題と最も密接に一致する問題に関する ChatGPT でのパフォーマンスを評価しました。
Prompt Engineering
プロンプトエンジニアリングが生成 LLM の出力に大きな影響を与えることが示されているため、AMBOSS および NBME データセットの入力形式を標準化しました [16]。まず、ChatGPT はテキスト入力しか受け付けないため、画像を含む質問を削除しました。次に、回答が表としてフォーマットされている質問を削除しました。これは、ChatGPT の回答の精度が、複雑なテキスト入力を解析するのではなく、ナラティブのテキスト内で医学的知識を統合する能力にのみ依存するようにするために行われました。質問は、質問テキストの後に改行で区切られた直接の質問が続く形式で作成されました。AMBOSS データ セットでは、ヒント(ATTENDING TIPS)が質問の別の事例として挿入されました。質問テキストと直接質問に続いて、またもや改行で区切られた多肢選択式の回答が提示されました。
質問プロンプトと応答の例を図 1 に示します。
 |
| 図1.出典:https://mededu.jmir.org/2023/1/e45312 |
キャプション:各大規模言語モデル (LLM) に提示された質問のテンプレート。これは AMBOSS のヒント(ATTENDING TIPS)と、Chat Generative Pre-trained Transformer (ChatGPT) からの応答の両方を含みます。この質問の正解は「E.ジドブジン(AZT)」。GPT-3 の場合、「この選択式の質問に答えてください:」 + 前述の質問 + 「正解は」というプロンプトエンジニアリングが必要でした。GPT-3 は本質的に非対話モデルであるため、これはモデルの幻覚(もっともらしい「ウソ」)を減らし、明確な答えを強制するために必要でした [17]。
Model Testing
最初に、AMBOSS および NBME データ セットにあるすべての正解を記録しました。すべてのモデル テストは、2022 年 12 月 15 日バージョンの ChatGPT で、ChatGPT Web サイトに手動で質問を入力して実行されました。OpenAI API を使用して、davinci モデルと text-davinci-003 モデルをそれぞれ使用して GPT-3 と InstructGPT をクエリしました。次に、標準化された質問をモデルに入力しました。また、ヒントを含む問題を ChatGPT に入力しました。すべての回答は、レビューのために共有スプレッドシートに直接コピーされました。各モデルの出力の性質上、各回答を手動で確認して、選択式の質問からどの回答が選択されたかを判断しました。
次に、語り口(ナラティブ)の一貫性に特徴的な 3 つのバイナリ変数を使用して、各質問の ChatGPT 応答が適切であることを証明しました [18]。より深い言語分析がなければ、これらの変数は以下を評価する大まかな指標を提供します:
- 論理的推論: 応答は、応答で提示された情報に基づいて回答を選択する際の論理を明確に識別します。
- 内部情報: 応答は、応答内の質問に関する情報を含む、質問の内部情報を使用します。
- 外部情報: 応答は、与えられた回答または語幹が適切であると証明することを含むがこれらに限定されない、質問の外部情報を使用します。
最後に、不正解の各質問について、不正解の理由を次の選択肢(オプション)のいずれかとしてラベル付けしました。
- 論理エラー: 応答は適切な情報を見つけましたが、情報を答えに適切に変換しませんでした。例: 若い女性が定期的にピルを服用するのが困難だとわかっているのに、依然として子宮内避妊器具よりも経口避妊薬を推奨する。
- 情報エラー: ChatGPT は、質問の語幹に存在するか、外部情報を介して存在するかに関係なく、予想される知識と見なされる重要な情報を特定できなかった。例:大部分がウイルス性である場合でも、ほとんどの症例は細菌性病因であると考えて、副鼻腔炎感染症の抗生物質を推奨した。
- 統計エラー: 算術ミスを中心とした誤差。これには、「1 + 1 = 3」などの明示的なエラーや、病気の有病率(罹患率)の誤った推定などの間接的なエラーが含まれます。例: 根底にある腎結石を特定しますが、さまざまな種類の結石の有病率を誤分類する。
回答の質的分析を行ったすべての著者 (AG、CWS、RAT、および DC) は協力して作業し、不確実なラベルはすべて全員で協議して一致させました。
Data Analysis
すべての分析は、Python ソフトウェア (バージョン 3.10.2; Python Software Foundation) を使って実施されました。対応のないカイ二乗検定を使用して、質問の難易度が AMBOSS-Step1 および AMBOSS-Step2 データセットでの ChatGPT のパフォーマンスに大きな影響を与えるかどうかを検定しました。同様に、対応のないカイ 2 乗検定を使って、NBME-Free-Step1 および NBME-Free-Step2 データ セットの正解と不正解の間の論理的推論、内部情報、および外部情報の分布を検定しました。
----------------------------------------
Results
----------------------------------------
Overall Performance
表 1 は、テストされた 4 つのデータ セットに対する 3 つの LLM: ChatGPT、GPT-3、および InstructGPT のパフォーマンスを示しています。AMBOSS モデルのスコアは、ヒントがない場合の値です。ChatGPT は、NBME と AMBOSS の両方のデータ セットに関して、ステップ 2 の質問と比較して、ステップ 1 関連の質問でより正確でした。すなわち、それぞれ 64.4% (56/87) 対 57.8% (59/102) および 44% (44/100) 対 42% (42/100)でした。さらに、このモデルは、ステップ 1 とステップ 2 の両方で、AMBOSS の質問よりも NBME の質問の方が優れたパフォーマンスを示しました: すなわち、それぞれ、64.4% (56/87) 対 44% (44/100) および 57.8% (59/102) 対 42% ( 42/100)でした。ChatGPT は、すべてのデータセットで GPT-3 と InstructGPT の両方を上回りました。InstructGPT は平均で 8.15% 優れていましたが、GPT-3 はすべての質問セットでランダム チャンスと同様のパフォーマンスを示しました。
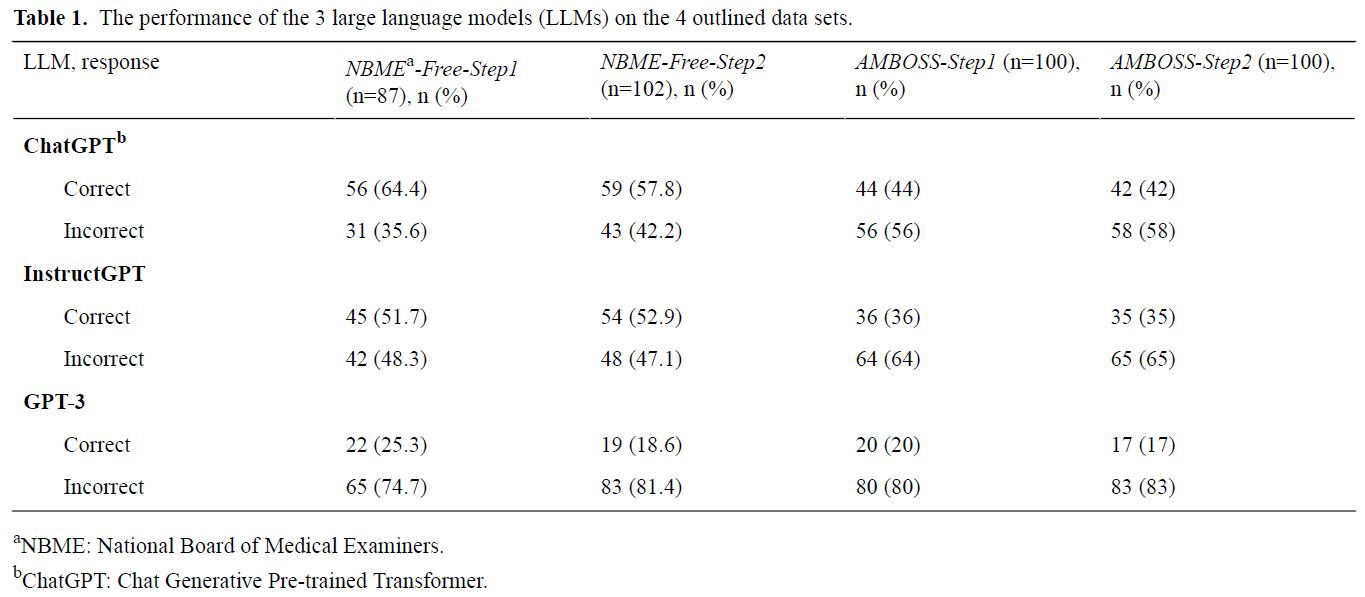 |
| 表1. 4 つの データ セットに対する 3 つの大規模言語モデル (LLM) のパフォーマンス。 |
Question Difficulty and Model Accuracy
表 2 から、テスト後の要約で報告された AMBOSS ユーザーと比較すると、ChatGPT は、ヒントなしのステップ 1 の質問で 30 パーセンタイル、ヒントがあるステップ 1 の質問で 66 パーセンタイルでした。ステップ 2 の AMBOSS データ セットでは、ヒントを使用した場合と使用しない場合で、モデルはそれぞれ 20 パーセンタイルと 48 パーセンタイルという結果でした。ヒントのないステップ 1 の質問では、ChatGPT は AMBOSS が報告した難易度が上がるにつれて精度が大幅に低下し (P=.01)、レベル 1 の質問では 64% (9/14) あった精度から レベル 5 の質問では 0% (0/14) に低下しました。残りのグループは、ヒントを使用したステップ 1 の難易度 2 と 3 の質問と、ヒントなしのステップ 2 の難易度 4 と 5 の質問を除いて、質問の難易度が上がるにつれて単調に精度が低下しました。
 |
| 表2.質問によるAMBOSS-Step1およびAMBOSS-Step2データセットでのChatGPTのパフォーマンス |
Qualitative Breakdown of Responses
最後に、表 3 では、上記の 3 つの指標で ChatGPT の回答の質を評価しました。すなわち、論理的推論、内部情報、および外部情報の存在の3つの指標です。ChatGPT によって提供されるすべての応答は、正解・不正解に拘わらず、その解答を選択した論理的な説明を提供することがわかりました。さらに、NBME-Free-Step1 と NBME-Free-Step2 の両方のデータ セットで、正解と不正解の両方について、ChatGPT は質問の 96.8% (183/189) で質問の内部情報を使用していました。ステップ 1 またはステップ 2 のいずれのデータセットについても、正解または不正解の間で、内部情報の存在に有意差はありませんでした (それぞれ P=.25 および P=.07)。最後に、ステップ 1 のデータセットでは、正解の場合は 92.9% (52/56) 、不正解の場合は 48.4% (15/31) の割合で、質問に含まれない外部の情報が使用されていました (差 44.5%; P<.001)。ステップ 2 のデータセットでは、外部情報は、正解の場合 89.8% (53/59) 、不正解の場合 62.8% (27/43) の割合で使用されていました (27% の差; P=.001)。ステップ 1 とステップ 2 の両方で、論理エラーが最も一般的で、次に情報エラーが続きました。どちらのデータセットにも統計誤差はほとんどありませんでした。
 |
| 表3.NBMEb-Free-Step1 および NBME-Free-Step2 に対する ChatGPT の応答品質の定性的分析 |
----------------------------------------
Discussion
----------------------------------------
Principal Findings
ChatGPT の進歩によって大袈裟に宣伝されている重要な機能の 1 つは、コンテキストを理解し、目の前のトピックに一貫性があり関連性のある会話を続ける能力です。この論文では、4 つの独自の医療知識能力データ セットで ChatGPT を評価し、会話を質問応答として構成することにより、これが医療領域にまで及ぶことを示しました。このモデルは、USMLE ステップ 1 およびステップ 2 医師免許試験でカバーされるトピックを表す試験問題の最大 60% 以上に正しく答えることができることがわかりました。多くの場合、60% のしきい値は、ステップ 1 とステップ 2 の両方のベンチマーク合格基準と見なされます。これは、ChatGPT が医学部 3 年生に期待されるレベルの能力を持っていることを示しています。さらに、私たちの結果は、間違った回答の場合でも、モデルによって提供された回答には常に回答選択の論理的な説明が含まれており、90% 以上の確率で、この回答には問題の主要な部分に含まれる情報が直接含まれていることを示しています。正解は、不正解の回答よりも (P<.001 [19] の有意確率で) 有意に頻繁に問題の主要部分以外の情報を含むことが判明しました。これは、モデルが質問に正しく答える能力は、プロンプトを問題内のデータに関連付ける能力に関連している可能性があることを示しています(※1)。
医学的質問応答研究の分野における以前の研究は、一般化可能性を犠牲にしてモデルのパフォーマンスを向上させることを目的として、より具体的なタスクに焦点を当てていることがよくありました。たとえば、Jin 等 [20] は、PubMed で利用可能なアブストラクトのコーパスで回答が見つかる可能性がある yes または no の質問に答えるモデルで 68.1% の精度を達成しました。より一般化可能なモデルの試みは、より多くの課題に直面しています。別の Jin 等の研究 [21] では、中国の医療免許試験から得られた 12,723 の問題のデータセットで 36.7% の精度を達成しました。同様に、2019 年に Ha 等 [22] は、454 の USMLE ステップ 1 およびステップ 2 の問題で 29% の精度しか達成できなかったと報告しています。したがって、ChatGPT は、単純な質問応答タスクを超えて拡張することで、3 つの異なる面で大きな前進を示しています。最初に、ChatGPT はテキストのみでフォーマットできるあらゆる質問に応答できるため、一般化可能性なことです。可能な質問の範囲は、ユーザーが送信できるものによってのみ制限されます。2 番目は精度です。ChatGPT は、同様の難易度と内容の質問で以前のモデルと同等またはそれを上回ることを示しました。最後に、ChatGPT は、その会話型インターフェイスにより、ユーザーの解釈可能性が大幅に向上しています。各回答には、私たちが示したようにある程度の推論があり、フォローアップの質問をする機能により、ユーザーは回答の出力だけでなく、質問で扱われている概念についてより大きな視点を得ることができます。
この対話的な性質が、教育ツールとして機能する能力において、ChatGPT を以前のモデルと区別するものです。InstructGPT は、すべてのデータ セットで ChatGPT を下回っていますが、ランダム チャンスを上回る精度でした。ただし、InstructGPT が ChatGPT と同等の精度で実行されたとしても、InstructGPT が提供した応答は、学生の教育に役立つものではありませんでした。InstructGPT の回答は、多くの場合、それ以上の説明がなく選択された回答のみであり、詳細なコンテキストを得るためにフォローアップの質問をすることはできません。InstructGPT は会話型システムとして体裁を整えているわけではないため、モデルは明確な回答を提供する前に、入力の促進を続行することがよくあります。たとえば、「G) せん妄」で終わるプロンプトは、回答が提供される前に「tremens B) 耳石の外れ」に展開されます。GPT-3 には同様のフォールバック(※2)があり、目的の出力を生成するにはよりプロンプト・エンジニアリングが必要です [17]。さらに、モデルはすべてのデータセットで ChatGPT と InstructGPT の両方をはるかに下回って(※3)いました。
ChatGPT の使用で強調すべき潜在的な使用例の 1 つは、少人数 (ピア) グループ教育の補佐役または代行人として使用することです。小グループ教育は、非常に効果的な教育方法であることが示されています [23,24]。医学教育における小グループの談話の促進の具体的な例としては、症例の提示を通じて取り組むことによる臨床上の問題解決が含まれます。このような教育へのアプローチは有用であり、学生の知識とは無関係です。これは、エール大学医学教育システムの入学後最初の週に始まる少人数グループ教育によって証明されています[26]。Rees 等 [27] はまた、仲間から教えられた学生は、教員から教えられた学生と有意に異なる結果をもたらさないことを示しました。多くの場合、有益な小グループ教育の側面は、生徒がお互いに自分で考えたアイデアをテストしあってフィードバックを受け取る能力が培われることです。ChatGPT は対話型のインターフェイスを備えているため、学生が独学で勉強しているときに、グループ学習と同じ利点の多くを提供できます。学生はこのツールを使用して、特定の医療概念、診断、または治療について質問し、正確でパーソナライズされた回答を受け取ることができ、各概念に関する知識をより適切に構築するのに役立ちます。たとえば、著者の CWS は、ChatGPT の使用について、最近のウイルス学の中間試験から特に困難な問題を検討しているとき、次のような考えを述べています。彼は、ChatGPT に問題を挿入し、フォローアップの対話に参加することに価値を見出しました。これにより、質問に関連するコンテキストが明らかになり、問題に関連する資料を教えた特定の講義を効果的に思い出すことができるからです。これは、ChatGPT が最初の回答で提供するコンテキストが、与えられた根底にある医学的推論を正当化するために必要な基礎知識を自然に掘り下げるさらなる質問への扉を開く可能性があることを示唆しています。小グループ教育のシミュレーションのための ChatGPT の特定の有効性、および有益である可能性のある他の使用例 (内省的学習のプロセスなど) を評価するには、さらなる研究が必要です [28]。技術がさらに探求され、改善されるにつれて、ChatGPT などのツールの機能を最大限に活用する新しい教育方法が開発される可能性もあります。
Limitations
この研究にはいくつかの限界があります。まず、ChatGPT は、2021 年以前に作成されたデータから作成されたコーパスで最初にトレーニングされました。これにより、モデルのプロンプトがその日付より前に見つかった情報のみを含むように制限されます。第二に、このモデルの閉じた性質とパブリック API の欠如により、タスク固有のデータでこのモデルを微調整し、本来備わっている偶然性の幅の広さを調べることができません。ただし、この研究では、USMLE ステップ 1 および 2 試験での ChatGPT のコンテキスト内でのパフォーマンスを調査しているため、これらの制限が分析を妨げることはありませんでした。第三に、ChatGPT は定期的に更新を受けています。これは、ユーザーから提供された入力に関するトレーニングの結果であると考えられています。この調査で使用された ChatGPT のバージョンは、公開時点で最新のモデルではありませんでした。とはいえ、モデルの新しいバージョンごとに、概説したタスクでモデルのパフォーマンスが大幅に低下することはなく、実際にはパフォーマンスが向上する可能性があるという仮説を立てることは合理的です。
【注意】
- ※1 この部分の論理展開がおかしい。「プロンプトを問題内のデータに関連付ける能力」ではなくて「プロンプトを問題外のデータに関連付ける能力」ではないか?
- ※2 「フォールバック」は「退却」「後退」に加えて「縮退運転(システムが故障したときに、プログラムによって機能を落として運転を継続しようとする仕組み)」という意味がある。ここでは「弱点」とか「欠点」のようなニュアンスでこの言葉が使われているような気がする。
- ※3 「下回って」ではなく「上回って」ではないか?
----------------------------------------
Conclusions
----------------------------------------
結論として、私たちの結果は、ChatGPT が、医学知識の主要な能力の評価に関して、3 年生の医学生に期待されるレベルで機能することを示唆しています。さらに、このツールは、医学における少人数グループ教育 (問題に基づく学習や臨床的問題解決など) の状況での新機軸としての可能性を秘めています。質問に対する ChatGPT の応答は、ほとんどの場合、モデルの書面による応答を正当化する解釈可能なコンテキストを提供し、談話の一貫性を示唆しています。このモデルは、人間の学習者に似た十分に正確な対話応答を提供することにより、学生向けのオンデマンドのインタラクティブな学習環境の作成を促進する可能性があります。これは、問題解決と外部からサポートされた内省的実践をサポートする可能性を秘めています。
この論文の 2 番目の結論として、ツールによって「次の原稿の結論を書いてください:」というプロンプトを使用して書いたものを紹介します。ただし、このプロンプトは、手書きの結論を除く全ての原稿を含んでいます。
結論として、この研究の目的は、医学知識と推論を評価する試験での ChatGPT 言語モデルのパフォーマンス、および仮想医療家庭教師として機能する能力を評価することでした。この研究では、AMBOSS-Step1 と AMBOSS-Step2、および NBME-Free-Step1 と NBME-Free-Step2 の 2 組のデータセットを使用して、USMLE Step 1 および Step 2 の 「臨床知識(Clinical Knowledge)」試験に関連する医学知識を ChatGPT が理解しているかを調べました。この研究の結果は、医学知識試験でのChatGPTのパフォーマンスがGPT-3およびInstructGPTのパフォーマンスよりも優れていること、およびヒント(Attending Tip)によって提供される追加のコンテキストがそのパフォーマンスを向上させることを示しました。さらに、この調査では、ChatGPT の応答は、論理的推論、内部情報の使用、および外部情報の使用に関して理路整然と[首尾一貫]していて分かりやすいことがわかりました。全体として、この研究は、ChatGPT が仮想の医療家庭教師として使用される可能性があることを示唆していますが、このコンテキストでのパフォーマンスと使いやすさをさらに評価するには、さらに研究が必要です。


0 件のコメント:
コメントを投稿