【論文概要】
電子カルテ(EMR)に蓄積された患者記録をドキュメント、SNOMED-CTでコーディングされた患者の健康状態(health conditions)を単語とみなしてトピックモデルを適用し、潜在的な健康状態のパターン(latent patterns of associated-conditions:これがトピック)を抽出するという研究。トピック数は20としている。
構築したトピックモデルを評価する方法として以下の2つの評価を行った。
- 医学的な妥当性の評価(定性的な評価)
- 弁別性(distinctiveness)と気密性(tightness)による定量的な評価
前者は、同一トピック内に高確率で出現する健康状態が関連しあっているかどうかを医学文献で検証することによって妥当性の評価を行っている。
後者の弁別性(distinctiveness)は、トピックの単語分布間のJensen-Shannon Divergenceを計算してトピック間の違いを定量的に評価している。
気密性(tightness)は1つのトピックがどのくらい少ない健康状態(SNOMED-CTコード)で表されるかを計算して評価している。
代表的な6つのトピックについて、出現確率の大きいものを10個抽出したところ、疾患の共起が医学文献で裏付けられたトピックが得られた。
20個のトピック間のJensen-Shannon Divergenceを計算したところ、平均値は0.666、中央値は0.692、そして最小値は0.483となった。Jensen-Shannon Divergenceは、2つの確率分布間の"距離"を表す量で、2つの分布が同一の場合は0に、まったくオーバーラップしない場合はln2 (~0.693)になるので、この結果は十分な弁別性を示している。
トピック内の出現確率が閾値(0.01)を超える健康状態(SNOMED-CTコード)の数を数えたところ、180あるSNOMED-CTコードのうち10以下のコードを合わせたものが9割を超えており、このことから十分な気密性を示していることがわかる。
【読後感】
LDAのテキストマイニング以外への応用としては興味深いものであった。しかし、医学文献による定性的な評価方法は説得力に欠く印象をぬぐえない。すべてのトピックについて検証したわけでもなさそうだし、類似したSNOMED-CTコードがLDAによってうまくグルーピングされたという客観的な証拠にはならないような気がする。
定量的評価方法については、弁別性(distinctiveness)といい気密性(tightness)といい計算が簡単な割には興味深い指標だと思った。しかし、これらはトピック間は健康状態空間における分布として大きく異なり、各トピックはわずかな健康状態で記述できる(高次元健康状態空間上のトピックが低次元健康状態空間で表現されている)ということを言っているだけで、トピックの解釈については何も触れていない。
最後に、なぜトピック数が20なのか根拠が示されていない(トピック数を14にしても結果はあまり変わらなかったとは書いていたが)。
【概要】
ICU退院後の死亡率(post-discharge ICU mortality)の正確な予測と透明性のある予測モデルの作成を目的に、ICD-9-CMコードをラベルに用いたLabeled-LDA (Latent Dirichret Allocation)を使って患者の診療記録(medical notes)から理解可能なトピック特性表現(topic feature representations)を取り出した。
近年、トピックモデルを用いて死亡率の予測精度を改善しようという試みが行われているが、トピックそのものはフラットな単語の集まりに過ぎず、その臨床的な解釈には専門家による吟味が必要となる。
この研究では解釈可能なトピックを自動的に定義する手法を提案している。その手法とは、ICD-9-CMコードをLabeled-LDAのトピックに用いてモデルの学習を導き、診療記録から理解可能なトピック特徴表現(understandable topic feature representations)を抽出するという方法である。
Labeled-LDAのラベルとしてICD-9-CMを用いる利点には次の2つがある。
- ある患者の診療記録はその患者に割り当てたICD-9-CMコードに対応するトピックにのみ寄与する
- トピックの解釈はICD-9-CMコードの定義とそのトピックに含まれる単語集合をとおして達成される
モデルを訓練する段階ではICD-9-CMコードを使っている。しかしながら、患者が退院してしまうとICD-9-CMコードは利用できなくなるので、予測モデルの特徴量としてICD-9-CMコードを直接含めることができない。Labeled-LDAを使えばこの問題を回避できる。なぜならば、予測段階ではICD-9-CMコードに対応するトピックの割合を推測するのにICD-9-CMコードを必要としないからである。これは、トピックに高確率で含まれる単語を特徴量に用いて文書のトピック含有率を予測するからである。
【評価方法】
提案手法の評価は、得られたトピック含有率を特徴量に用いてSVMでICU退院後の死亡率(post-discharge ICU mortality)を予測することによって行っている。すなわち、外部基準として予測の精度を用いているわけである。死亡率の予測は、もとをただせば死亡/生存の分類問題であるから本質的にこれまで読んできた文献と同じである。トピックモデルの評価はやはりこれしかないのだろうか。
予測する死亡率は30日後と6か月後の2つで、6か月後死亡率の予測SVMモデルの特徴量に用いるのは以下の3パターンである。
- ベースライン:年齢、性別、入院時のSAPS-Ⅱスコア(ICUの重症度スコア)、最小SAPS-Ⅱスコア、最大SAPS-Ⅱスコア、Elixhauser Comorbidity Index(30個のへ依存症を考慮に入れたICU重症度の補正指標)
- ベースライン+通常のLDAから得られた50個のトピック含有率
- ベースライン+Labeled-LDAから得られた50個のトピック含有率(提案手法)
30日死亡率予測モデルでは、最小SAPS-Ⅱスコア、最大SAPS-Ⅱスコア、ICD-9-CM由来のElixhauser Comorbidity Indexを特徴量から取り除いている。これは、ICD-9-CMコードの割り当ては通常退院後2週間まで有効とされているからで、それ以降はICD-9-CM由来のElixhauser Comorbidity Indexを特徴量に用いることは適切ではないからである。
【結果】
最も予測精度が高かったのは、baseline + LDA with 50 topicsで、30日死亡率の予測でAUCが0.860、6か月死亡率は0.842だった。次いで baseline + Labeled-LDA with 111 labelsで、各々0.835、0.829だった。これに対してbaselineのみでは、それぞれ0.736、0.776であった。
この結果からLDAで得たトピック成分を特徴量に用いると予測精度が高くなることが分かったが、Lableled-LDAよりも純粋なLDAの方が精度が高いという結果となった(Table 2)。これは、本文に書かれていることと矛盾する。
しかし、Discussionに書かれているように純粋なLDAは専門家によるトピックの解釈が必要になる。これに対してLabeled-LDAを用いればTable 3に示すようなトピック別(つまりICD-9-CMコード別)死亡率を推定できる。
また、興味深いことにLabeled-LDAモデルは、トピックに関連付けられた単語によって、潜在的に異なる疾患の間の関係を発見する能力を持っている。例えば、"Other metabolic and immunity disorders(他の代謝疾患及び免疫疾患)"に関連付けられたトピックに頻出する単語に、chest(胸部)、artery(動脈)、coronary(冠状)、cabg(冠動脈バイパス手術)などがあるが、これは循環器疾患と代謝疾患に関連性があることを示している。これは、ラベルの頻度や相互依存性を考慮したLabeled-LDAを用いれば異なるラベル間の相関を探索できる可能性があることを示唆している。
【読後感】
Labeled-LDAというものをはっきりと勉強したわけではないのでぼんやりとしか理解できないのだが、この手法は、LDAの大きな欠点である「得られたトピックの解釈困難性」を緩和する手法のように思われる。
モデルを学習するときラベルを与えることにより、トピックを明示的に定義できる。つまり、
当該トピックに関連するドキュメントのみを与えることによってトピックの意味をモデルに教えている。LDAと同じように得られたトピックは単語分布になる。これを用いてトピックの予測は単語を使って行うが、トピックにはラベルが対応しているので、それを用いてトピックの意味を解釈できる。つまり、こうだ。モデルに文書を与えると、モデルは文書のトピック分布を返す。各トピックにはラベルがついているので、その文書の解釈が可能となる。
これは
文献[2]と手法が似ていると感じた。
文献[2]では請求データというドキュメントから疾患というトピックを推測し、その中で最もコストのかかったトピック(疾患)を最大資源投入疾患としている。そこでもLabeled-LDAを用いている(ラベルはDPCコード?)。
この論文を読んで感心したのは、
- 退院後はICD-9-CMコードが付与されていないにも拘わらず、ICD-9-CM別の死亡率を予測できること
- トピックに高確率で含まれる単語を用いて疾患間の関係を調べることができること
である。
Yen-Fu Luo, Anna Rumshisky: Interpretable Topic Features for Post-ICU Mortality Prediction. AMIA 2016 Annual Symposium Proceedings, 827-836, 2016.
【論文概要】
DMPM(disease-medicine pattern model)という拡張版トピックモデルを使って大量の保険請求データを解析し、疾患と処方薬の関係から処方パターンを抽出した。
この研究では処方せんをドキュメント、その中に含まれる疾患(ICDコード)や処方薬を単語、処方パターンをトピックとみなしている。
DMPMの生成プロセスを図1に示す。
 |
| 図1.DMPMの生成プロセス |
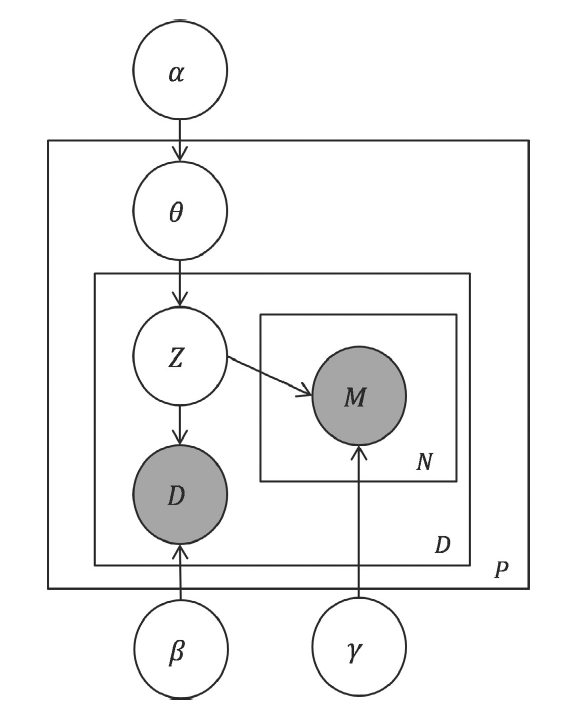
また、グラフィカルモデルを図2に示す。
 |
| 図2. DMPMのグラフィカルモデル |
DMPMはLDAを拡張して各々の処方せんについて処方薬と疾患を生成するプロセスを加えている。
疾患は、図1のBのiiで生成し、医薬品はBのiiiのaで生成している。
通常のLDAであれば、図2において、ハッチのかかったノードDが単語に相当し、一番外側の四角はドキュメントの繰り返し、その内側の四角は単語の繰り返しを表し、ノードMに相当する確率変数はない。
これに対してDMPMでは、個々の患者pに対してトピック分布(この論文ではトピックという用語ではなくパターンという用語を使っている)θ
pをαをパラメタとするディリクレ分布から生成し、その患者に対して発行された個々の処方せんのトピックz
p,rをθ
pをパラメタとする多項分布から生成する。疾患d(図2中のノードDのインスタンス)は、トピックz
p,r=kに対するβ
kをパラメタとする多項分布から生成する。また、処方薬m(図2中のノードMのインスタンス)は、トピックz
p,r=kに対するγ
kをパラメタとする多項分布からN
pr個生成する。
このモデルで推定するパラメタは
- θp = {θp,k}:患者pにトピックkが含まれる割合(患者pのトピックk含有率)
- βk = {βk,d}:トピックkに疾患dが含まれる割合(トピックkの疾患d含有率)
- γk = {γk,m}:トピックkに医薬品mが含まれる割合(トピックkの医薬品m含有率)
の3つである。
【評価方法】
得られたモデルの評価方法としては、これまでは最大トピック含有率を与えるトピックでドキュメントを分類したり
[1]、トピック含有率を新たな特徴量に使って分類問題の精度を比較する
[5]といった外部基準を使った評価手法が多かった。
この研究では{β
k,d}や{γ
k,m}でパターン(トピック)間の類似度(cosine類似度、K-L divergence、Jensen-Shannon divergence)を計算し、他の手法(ICDコードによるグルーピングや疾患LDA、医薬品LDA)に比べて年齢、性別、居住地などの患者属性による違いをどのくらい顕著に区別できるかを定量的に評価している。
一例として年齢による患者の多様性をDMPMとICDによるカテゴリ化で比べたのが図3である。
 |
| 図3. 年齢による多様性の捕捉(上:DMPM、下:ICD) |
 |
| 図4.他のグルーピング手法との比較 |
【読後感】
著者らはICDのような標準コードを用いた疾患のカテゴリ化を「トップダウン方式」と呼び、それに対して提案手法によるデータに基づいたカテゴリ化を「ボトムアップ方式」と呼んで両者の比較を行っている。
また、それらの類似点や差異をもとに本手法の妥当性(ICDによるカテゴリをある程度再現しているから妥当だ)の評価と有効性(ICDによるカテゴリ化では説明できない事実を捉えているので有効だ)を議論している。
たとえば同じ疾患でも使用する医薬品が異なるとか逆に異なる疾患に同じ医薬品を処方しているかといった知見を得ている。
この研究の興味深い点は疾患と医薬品の両方を単語とみなしてLDAを拡張しているところである。これによってパターン(トピック)を疾患含有率ベクトル{β
k,d}と医薬品含有率ベクトル{γ
k,m}の2通りで表現し疾患と医薬品の相関を議論している。
ドキュメントにラベルが付けられていたら図3のようなグラフを描いて、トピックモデルを使った場合とラベルだけを使った場合でどのような違いが見られるか(ラベルだけでは捕捉できないどのような特徴をトピックモデルで捉えることができるか)を議論するのは興味深い。
また、図5のようなグラフを描いてラベル別のトピック含有率を比較するのも面白いかもしれない。
 |
| 図5.ICDによるカテゴリ化とDMPMによるパターンとの比較 |
【モデル選択】
この論文ではモデル選択(最適なトピック数の推定)手法としてPerplexityとpredictive log-likelihoodの2つの方法を用いてトピック数=15が最適であるとしている。
RのtopicmodelsパッケージにはPerplexityを計算するメソッドはあるが、predictive log-likelihoodの計算メソッドは見当たらない。
predictive log-likelihoodは未知データR
newを使ってP(R
new)で計算する。topicmodelsのLDAメソッドは訓練データからモデルを作成する。LogLiksというメソッドを使えば作成したモデルからlog-likelihoodを計算できるが、これはP(R
train)なので、トピック数Kを増やせばいくらでも大きくすることができる(オーバーフィッティング)。
P(R
train)を計算するメソッドはないのだろうか。"
Perplexity To Evaluate Topic Models"にはPerplexityはpredictive log-likelihoodと等価であると書いてあるが・・・。
P(R
new)を計算する方法を考えてみよう。LDAの生成モデルでは、ドキュメントr∈R
newのトピック分布θ
kからトピックkを選び、トピックkの単語分布φ
k,wから単語wを選択した結果、単語wがrに現れると考える。これをR
newだけで計算するにはどうすればよいのだろう?そもそも、単語wがどのトピックから生成されたなどどうしてわかるのだろうか?単語wはトピックkからφ
k,wの確率で生成されるのだから単語だけではトピックは決定できない。
これがpredictive log-likelihoodの計算メソッドが提供されていない理由なのかもしれない。
しかし、この論文では(8)式を使ってpredictive log-likelihoodを計算している。ポイントはwのトピックkなどわからないので、期待値E[θ
k|R
obs,Θ]を使って近似しているところだ。これを使えば最終的にpredictive log-likelihoodはモデルのパラメタ{β
k,d}、{γ
k,m}を使って(9)式で求めることができるとのこと(途中の式の展開はよくわからないのでフォローできていない)。これを用いて図6に示すpredictive log-likelihoodのトピック数K依存性が得られたということである。
 |
| 図6.predictive log-likelihoodのパターン数(トピック数)依存性 |
訓練データを用いて計算したlog-likelihoodはトピック数の増加に伴っていくらでも増加する。これはモデルがデータにオーバーフィッティングしているためだと考えられる。したがってトピック数Kの決定にはpredictive log-likelihoodを用いるべきではないだろうか。
論文中の式(8)のE[θ
k|R
obs,Θ]はどのようにして求めるのだろうか?
Park S, Choi D, Kim M, Cha W, Kim C, Moon IC: Identifying prescription patterns with a topic model of diseases and medications. Journal of Biomedical Informatics archive, 75C, 35-47, 2017.